
多路搜索树(multi-way search tree):
B树就是B-树:
B树的阶。B+树:
数据库索引主要基于什么数据结构?
hash表和B+树
数据库索引为什么要用B+树结构来存储呢?
树的查询效率高。而且可以保持有序。但是为什么不用二叉查找树呢?主要是因为磁盘I/O的影响,数据库索引是存储在磁盘上的,当数据量比较大的时候,索引的大小可能有几个G甚至更多。当我们利用索引查询时候,能把整个索引全部加载到内存吗?很显然不可能的,我们能做的是逐一加载每一个磁盘页,这里的磁盘页面对应着索引树的节点。这样的话,每遍历到一个节点就需要进行一次I/O操作。
磁盘这种外部存储器适合批量式的访问,为了减少I/O,我们需要把原本瘦高的树结构变得矮胖,这就是B-树的特征之一。
大规模数据存储中,实现索引查询这样一个实际背景下,树节点存储的元素数量是有限的,如何减少树的深度?
一个基本的想法就是:采用多叉树结构(由于树节点元素数量是有限的,自然该节点的子树数量也就是有限的)
B-树主要应用于文件系统以及部分数据库索引,比如著名的非关系型数据库MongoDB。
所谓m阶B-树,即为m路平衡搜索树(m大于等于2),除了根节点,各个节点的分支数目介于[M/2向上取整, M]。
M为设定的非叶子结点最多子树个数,N为关键字总数。
由于限制了除根结点以外的非叶子结点,至少含有M/2个儿子,确保了结点的利用率,其最底搜索性能为:O(log n)
中间节点都包含k-1个元素和k个孩子,其中 m/2 <= k <= m叶子节点都包含k-1个元素,其中 m/2 <= k <= m举一个B-树的例子,一个3阶的B-树,也就是(2,3)-树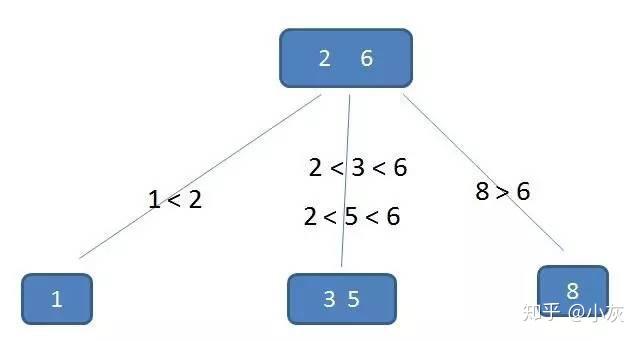
对于这颗树查询的过程比较次数不比二叉查找树少,尤其当单一节点中的元素数量很多的时候,可是相对于磁盘I/O,内存中的比较耗时几乎可以忽略,所以可以提升查找的性能。
优势,自平衡
遵循规则:

自顶向下查找4的节点位置,发现4应当插入到节点元素3,5之间。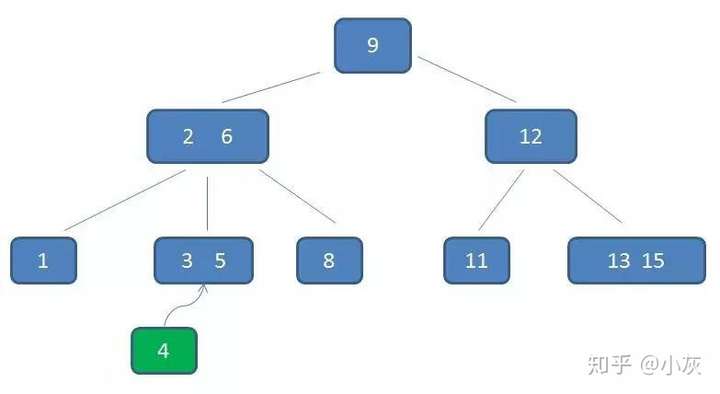
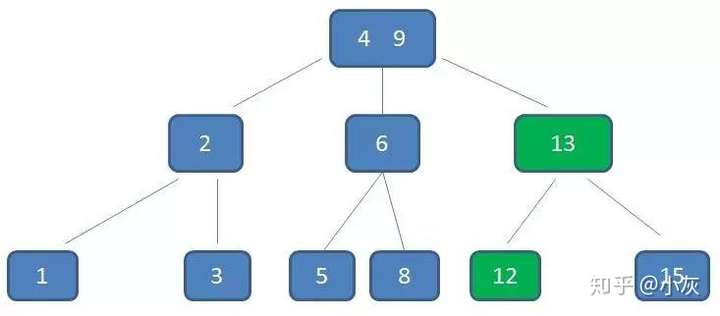
节点3,5已经是两元素节点,无法再增加。父亲节点 2, 6 也是两元素节点,也无法再增加。根节点9是单元素节点,可以升级为两元素节点。于是拆分节点3,5与节点2,6,让根节点9升级为两元素节点4,9。节点6独立为根节点的第二个孩子。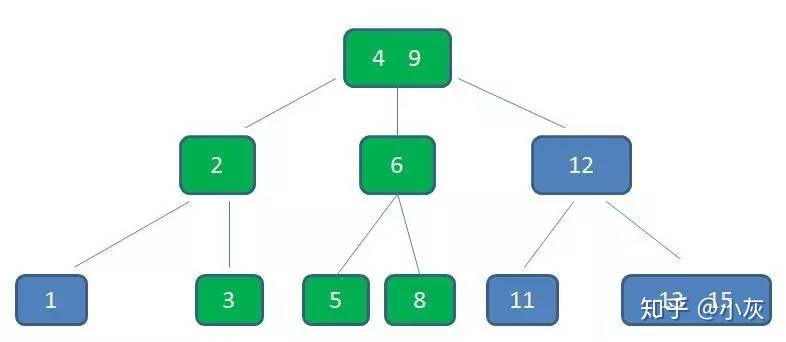
遵循规则:
自顶向下查找元素11的节点位置。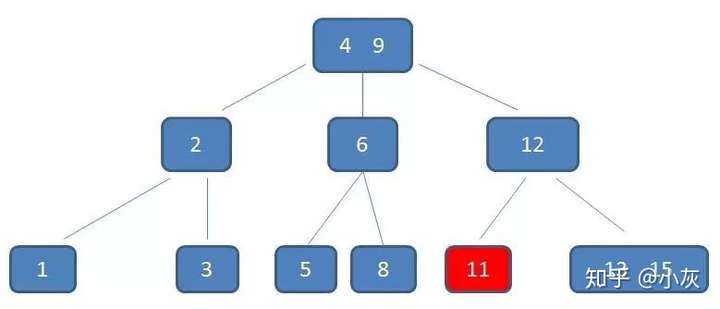
删除11后,节点12只有一个孩子,不符合B树规范。因此找出12,13,15三个节点的中位数13,取代节点12,而节点12自身下移成为第一个孩子。(这个过程称为左旋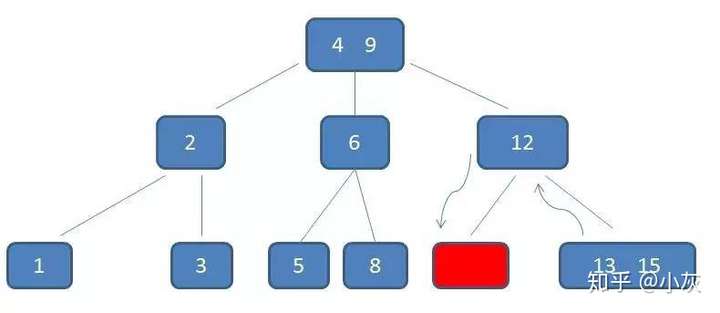
卫星数据(Satellite Information):指的是索引元素所指向的数据记录,比如数据的某一行。在B-树中,无论中间节点还是叶子节点都带有卫星数据。
B-树中的卫星数据(Satellite Information):无论是叶子节点还是中间节点都带有卫星数据。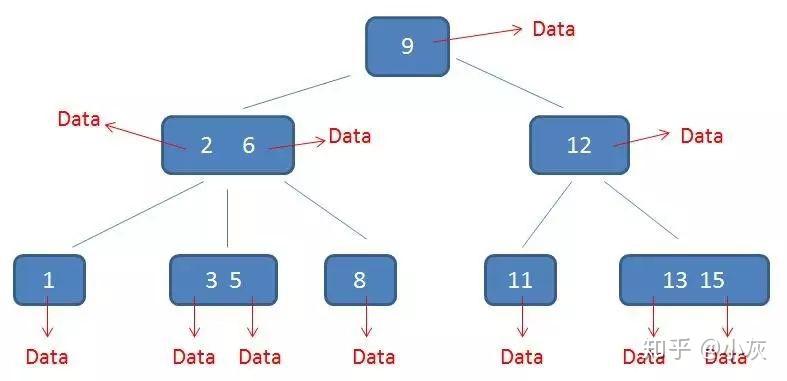
比方对于上面的B-树,我们想查找3到11的元素,只能依靠繁琐的中序遍历。
B+树是B树的一个升级版,相对于B树来说B+树更充分的利用了节点的空间,让查询速度更加稳定,其速度完全接近于二分法查找。
B+树是对B树的一种变形树,它与B树的差异在于:
一个m阶的B+树具有如下几个特征:
示例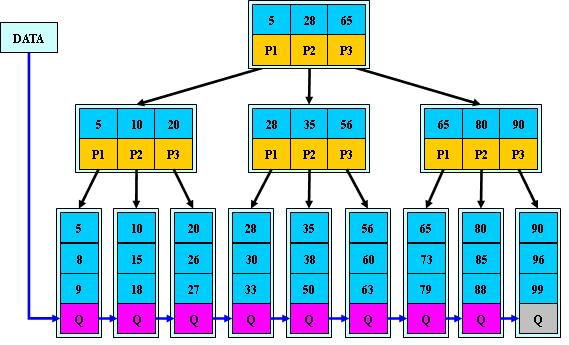

卫星数据(Satellite Information):指的是索引元素所指向的数据记录,比如数据的某一行。在B-树中,无论中间节点还是叶子节点都带有卫星数据。
B+树中的卫星数据(Satellite Information):只有叶子节点带有卫星数据。中间节点仅仅是索引,没有任何关联数据。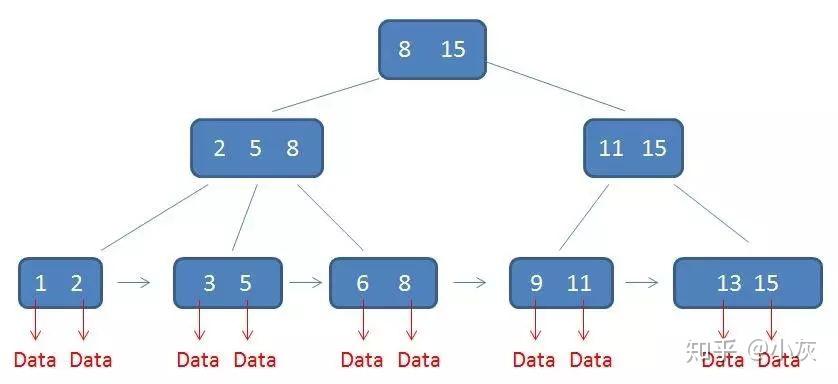
需要补充的是,在数据库的聚集索引(Clustered Index)中,叶子节点直接包含卫星数据。在非聚集索引(NonClustered Index)中,叶子节点带有指向卫星数据的指针。
相对于B-树要简单的多,只需要在链表上做遍历即可!
B+树的优点:
由于B+树在内部节点上不好含数据信息,因此在内存页中能够存放更多的key。 数据存放的更加紧密,具有更好的空间局部性。因此访问叶子几点上关联的数据也具有更好的缓存命中率。
B+树的叶子结点都是相链的,因此对整棵树的便利只需要一次线性遍历叶子结点即可。而且由于数据顺序排列并且相连,所以便于区间查找和搜索。而B树则需要进行每一层的递归遍历。相邻的元素可能在内存中不相邻,所以缓存命中性没有B+树好。
B树的优点:
B+树的磁盘读写代价更低:B+树的内部节点并没有指向关键字具体信息的指针,因此其内部节点相对B树更小,如果把所有同一内部节点的关键字存放在同一盘块中,那么盘块所能容纳的关键字数量也越多,一次性读入内存的需要查找的关键字也就越多,相对IO读写次数就降低了。
B+树的查询效率更加稳定:由于非终结点并不是最终指向文件内容的结点,而只是叶子结点中关键字的索引。所以任何关键字的查找必须走一条从根结点到叶子结点的路。所有关键字查询的路径长度相同,导致每一个数据的查询效率相当。
B+树的范围查询更加方便:由于B+树的数据都存储在叶子结点中,分支结点均为索引,方便扫库,只需要扫一遍叶子结点即可,但是B树因为其分支结点同样存储着数据,我们要找到具体的数据,需要进行一次中序遍历按序来扫,所以B+树更加适合在区间查询的情况,所以通常B+树用于数据库索引。
B树在提高了IO性能的同时并没有解决元素遍历的我效率低下的问题,正是为了解决这个问题,B+树应用而生。B+树只需要去遍历叶子节点就可以实现整棵树的遍历。而且在数据库中基于范围的查询是非常频繁的,而B树不支持这样的操作或者说效率太低。
B-树和B+树都是很基础的概念,需要掌握好啊!
二叉搜索树:
B(B-)树:
B+树:
B*树:
漫画:什么是B+树?
从B树、B+树、B*树谈到R 树
平衡二叉树、B树、B+树、B*树 理解其中一种你就都明白了
漫画:什么是B-树?
从二叉查找树到B+树中间的各种树 //写的相当不错
B-树 百度百科
阿里面试,问了B+树,这个回答让我通过了
数据结构 邓俊辉
Update your browser to view this website correctly. Update my browser now