
实体(entity):客观存在并可相互区别的事物称为实体。
实体型(entity type):用实体名及其属性名集合来抽象和刻画同类实体,称为实体型。
实体集(entity set):同一实体型的集合称为实体集。
| 关系模型的数据结构术语 | 一般表格的术语 |
|---|---|
| 关系名 | 表名 |
| 关系模式 | 表头(表格的描述) |
| 关系 | (一张)二维表 |
| 元组 | 记录或者行 |
| 属性 | 列 |
| 属性名 | 列名 |
| 分量 | 一条记录中的一个列值 |
| 域 | 值的集合,值的取值范围 |
| 非规范关系 | 表中有表 |
关系模型(relational model)
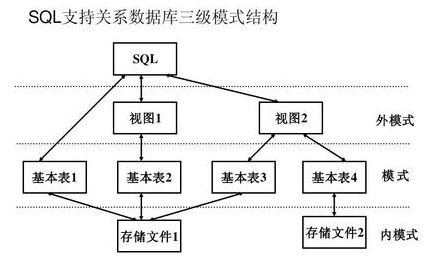
基本表:实际存在的表,实际存储数据的逻辑表示
查询表:查询结果对应的表
视图表:由基本表或其他视图导出来的表,是虚表,不对应实际存储的数据。
实体完整性
参照完整性:指的是关系之间存在着属性的引用,比如学生(学号,姓名,专业号),专业(专业号,专业名)。学生这个表参照了专业表里的专业号
用户定义的完整性
用户自己设置的规则,比如某个属性的范围,某个属性必须取为唯一值等。
并 差 交 笛卡儿积称为集合运算.
(1) 并(Union)
并是抽取两个表格中所有行的运算,经过并运算后能够抽取两个表格中的所有数据.
(2) 差(difference)
能够调取两张表中其中一张表独有的数据,这种运算叫做差,以不同的表格为基准会获得不同的运算结果.
(3) 交(intersection)
能够调取两张表格共有数据的这种运算叫做交.
(4) 笛卡儿积(Cartesian product)
笛卡儿积是一种可以将两个表格中所有数据排列组合的方法
(5) 投影(projection)
抽取列的运算叫做投影.投影是调取表中某一列.
(6) 选择(Selection)
选择是调取表中某一行的运算.
(7) 连接(join)
连接就是将表格连接起来.外键参照其他表中的主键,通过连接,将两个表格粘合起来. 笛卡尔集中选取合适的;
等值连接 选取某些属性的值相等的那些元组
自然连接 重复的属性列去掉
(8) 除
除就是从’被除表格’中调取’除表格’中包含的所有行,然后再从中去掉’除表格’中所有行的运算.
| 对象类型 | 对象 | 操作类型 |
|---|---|---|
| 数据库模式 | 模式 | CREATE SCHEMA |
| 基本表 | CREATE SCHEMA,ALTER TABLE |
|
| 视图 | CREATE VIEW |
|
| 索引 | CREATE INDEX |
|
| 数据 | 基本表和视图 | SELECT,INSERT,UPDATE,DELETE,REFERENCES,ALL PRIVILEGES |
| 属性列 | SELECT,INSERT,UPDATE,REFERENCES,ALL PRIVILEGES |
SELECT - 从数据库中提取数据
UPDATE - 更新数据库中的数据
DELETE - 从数据库中删除数据
INSERT INTO - 向数据库中插入新数据
CREATE DATABASE - 创建新数据库
ALTER DATABASE - 修改数据库
CREATE TABLE - 创建新表
ALTER TABLE - 变更(改变)数据库表
DROP TABLE - 删除表
CREATE INDEX - 创建索引(搜索键)
DROP INDEX - 删除索引
一个低一级范式的关系模式通过模式分解可以转换为若干高一级范式的关系模式的集合,这个过程叫规范化 。//通俗的说,就是为了方便增删改查才转为为各种范式。
第一范式(1NF):属性(字段)是最小单位不可再分。 //不可以一个属性里面的值还可以再分为多个值
第二范式(2NF):满足 1NF,每个非主属性完全依赖于主键
关系模式的简化三元组 R<U,F> F是属性组上面的一组数据依赖。
数据依赖
事务:用户定义的一个数据库操作序列,这些操作要么做,要么不做,是一个不可分割的工作单位
一个程序包含多个事务
事务的开始可以由用户显式控制。如果用户没有显式义,由DBMS按照默认规定自动划分事务。
在SQL中,定义事务的语句一般是三条
1 | BEGIN TRANSCTION; |
原子性:事务要么做要么不做
一致性:事务前后数据的完整性必须保持一致。
隔离性:事务的隔离性是多个用户并发访问数据库时,数据库为每一个用户开启的事务,不能被其他事务的操作数据所干扰,多个并发事务之间要相互隔离。
持久性:持久性是指一个事务一旦被提交,它对数据库中数据的改变就是永久性的,接下来即使数据库发生故障也不应该对其有任何影响
恢复的实现技术:建立冗余数据 -> 利用冗余数据实施数据库恢复。
建立冗余数据常用技术:数据转储(动态海量转储、动态增量转储、静态海量转储、静态增量转储)、登记日志文件。
事务是并发控制的基本单位。
并发操作带来的数据不一致性包括:丢失修改、不可重复读、读 “脏” 数据。
并发控制主要技术:封锁、时间戳、乐观控制法、多版本并发控制等。
基本封锁类型:排他锁(X 锁 / 写锁)、共享锁(S 锁 / 读锁)。
活锁死锁:
活锁:事务永远处于等待状态,可通过先来先服务的策略避免。
死锁:事物永远不能结束
预防:一次封锁法、顺序封锁法;
诊断:超时法、等待图法;
解除:撤销处理死锁代价最小的事务,并释放此事务的所有的锁,使其他事务得以继续运行下去。
可串行化调度:多个事务的并发执行是正确的,当且仅当其结果与按某一次序串行地执行这些事务时的结果相同。可串行性时并发事务正确调度的准则
语言简洁,易学易用
SQL的动词
1 | 数据查询 SELECT |
综合统一
基本操作对象有:模式、表、视图和索引
1 | 操作对象| 创建 | 删除 | 修改 |
SQL不提供修改模式定义和修改视图定义的操作,如果想修改就只能删除然后重建;
示例
1 | CREATE SCHEMA test AUTHORIZATION zhang |
1 | 删除模式 |
索引的建立和删除
表太大的时候,查询操作会比较耗时,可以用索引来加快。
在基本表上建立一个或者多个索引,加快查找速度
数据库索引类型
建立索引和删除索引由数据库管理员或者表的建立者负责完成。
但是查询时候是由数据库管理系统自动选择合适的索引,用户不能显式选择。
是数据库管理系统中的一组系统表,记录了数据库所有的定义信息
关系数据库执行SQL相关的数据定义语句的时候,实际上就是在更新数据字典表中的信息。
1 | SELECT [ALL|DISTINCT] <目标列表达式> [<目标列表达式 >]... //DISTINCT 取消重复值,ALL 不取消重复值 |
1 | INSERT |
1 | UPDATE student |
1 | //只能删除元组 |
1 | CREATE VIEW IS_STUDENT |
1 | DROP VIEW <视图名>[CASCADE] //级联代表删除相关联的视图 |
数据库系统概论 王珊 萨师煊
SQL 语法
数据库篇(每位开发者必备)
Update your browser to view this website correctly. Update my browser now