/** * register_filesystem - register a new filesystem * @fs: the file system structure * * Adds the file system passed to the list of file systems the kernel * is aware of for mount and other syscalls. Returns 0 on success, * or a negative errno code on an error. * * The &struct file_system_type that is passed is linked into the kernel * structures and must not be freed until the file system has been * unregistered. */ intregister_filesystem(struct file_system_type * fs) { int res = 0; structfile_system_type ** p;
BUG_ON(strchr(fs->name, '.')); if (fs->next) return -EBUSY; write_lock(&file_systems_lock); //对该链表的查找加了写锁write_lock p = find_filesystem(fs->name, strlen(fs->name)); if (*p) res = -EBUSY; else *p = fs; write_unlock(&file_systems_lock); return res; }
EXPORT_SYMBOL(register_filesystem);
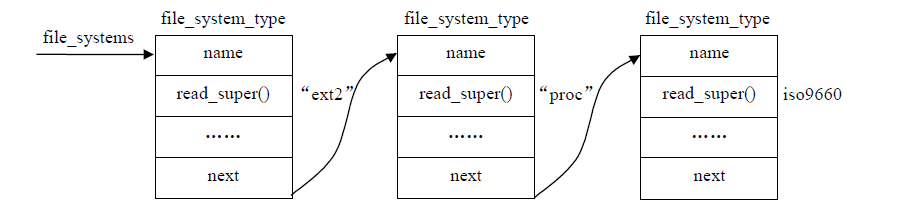
find_filesystem()函数在同一个文件中定义如下:
1 2 3 4 5 6 7 8 9
static struct file_system_type **find_filesystem(constchar *name, unsigned len) { structfile_system_type **p; for (p=&file_systems; *p; p=&(*p)->next) if (strlen((*p)->name) == len && strncmp((*p)->name, name, len) == 0) break; return p; }
/** * unregister_filesystem - unregister a file system * @fs: filesystem to unregister * * Remove a file system that was previously successfully registered * with the kernel. An error is returned if the file system is not found. * Zero is returned on a success. * * Once this function has returned the &struct file_system_type structure * may be freed or reused. */ intunregister_filesystem(struct file_system_type * fs) { structfile_system_type ** tmp;
structmount { structlist_headmnt_hash;//安装点的哈希表 structmount *mnt_parent;//是指向上一层安装点的指针 structdentry *mnt_mountpoint;//指向安装点dentry 结构的指针 structvfsmountmnt; #ifdef CONFIG_SMP structmnt_pcp __percpu *mnt_pcp; #else int mnt_count; int mnt_writers; #endif structlist_headmnt_mounts;/* list of children, anchored here */ structlist_headmnt_child;/* and going through their mnt_child */ structlist_headmnt_instance;/* mount instance on sb->s_mounts */ constchar *mnt_devname; /* Name of device e.g. /dev/dsk/hda1 */ structlist_headmnt_list; structlist_headmnt_expire;/* link in fs-specific expiry list */ structlist_headmnt_share;/* circular list of shared mounts */ structlist_headmnt_slave_list;/* list of slave mounts */ structlist_headmnt_slave;/* slave list entry */ structmount *mnt_master;/* slave is on master->mnt_slave_list */ structmnt_namespace *mnt_ns;/* containing namespace */ structmountpoint *mnt_mp;/* where is it mounted */ #ifdef CONFIG_FSNOTIFY structhlist_headmnt_fsnotify_marks; __u32 mnt_fsnotify_mask; #endif int mnt_id; /* mount identifier */ int mnt_group_id; /* peer group identifier */ int mnt_expiry_mark; /* true if marked for expiry */ int mnt_pinned; int mnt_ghosts; };
/* * Flags is a 32-bit value that allows up to 31 non-fs dependent flags to * be given to the mount() call (ie: read-only, no-dev, no-suid etc). * * data is a (void *) that can point to any structure up to * PAGE_SIZE-1 bytes, which can contain arbitrary fs-dependent * information (or be NULL). * * Pre-0.97 versions of mount() didn't have a flags word. * When the flags word was introduced its top half was required * to have the magic value 0xC0ED, and this remained so until 2.4.0-test9. * Therefore, if this magic number is present, it carries no information * and must be discarded. */ longdo_mount(constchar *dev_name, constchar *dir_name, constchar *type_page, unsignedlong flags, void *data_page) { structpathpath; int retval = 0; int mnt_flags = 0;
/* * create a new mount for userspace and request it to be added into the * namespace's tree */ staticintdo_new_mount(struct path *path, constchar *fstype, int flags, int mnt_flags, constchar *name, void *data) { structfile_system_type *type; structuser_namespace *user_ns = current->nsproxy->mnt_ns->user_ns; structvfsmount *mnt; int err;
if (!fstype) return -EINVAL;
type = get_fs_type(fstype); if (!type) return -ENODEV;
if (user_ns != &init_user_ns) { if (!(type->fs_flags & FS_USERNS_MOUNT)) { put_filesystem(type); return -EPERM; } /* Only in special cases allow devices from mounts * created outside the initial user namespace. */ if (!(type->fs_flags & FS_USERNS_DEV_MOUNT)) { flags |= MS_NODEV; mnt_flags |= MNT_NODEV; } }
/* * add a mount into a namespace's mount tree */ staticintdo_add_mount(struct mount *newmnt, struct path *path, int mnt_flags) { structmountpoint *mp; structmount *parent; int err;
mp = lock_mount(path); if (IS_ERR(mp)) return PTR_ERR(mp);
parent = real_mount(path->mnt); err = -EINVAL; if (unlikely(!check_mnt(parent))) { /* that's acceptable only for automounts done in private ns */ if (!(mnt_flags & MNT_SHRINKABLE)) goto unlock; /* ... and for those we'd better have mountpoint still alive */ if (!parent->mnt_ns) goto unlock; }
/* Refuse the same filesystem on the same mount point */ err = -EBUSY; if (path->mnt->mnt_sb == newmnt->mnt.mnt_sb && path->mnt->mnt_root == path->dentry) goto unlock;
err = -EINVAL; if (S_ISLNK(newmnt->mnt.mnt_root->d_inode->i_mode)) goto unlock;
uapi文件夹:(the user space API of the kernel,Then upon kernel installation, the uapi include files become the top level /usr/include/linux/ files.)Linux Kernel 中新增的这些 uapi 头文件,其实都是来自于各个模块原先的头文件,最先是由 David Howells 提出来的。uapi 只是把内核用到的头文件和用户态用到的头文件分开。 Linux的系统调用都改为SYSCALL_DEFINE定义,原因参照:Linux系统调用之SYSCALL_DEFINE。